


















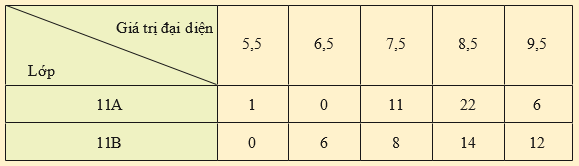
Thầy Tuấn thống kê lại điểm trung bình cuối năm của các học sinh lớp 11A và 11B ở bảng sau:
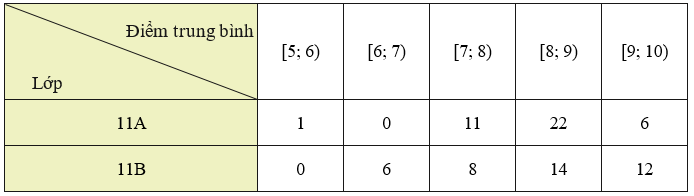
a) Nếu so sánh theo khoảng biến thiên thì học sinh lớp nào có điểm trung bình ít phân tán hơn?
b) Nếu so sánh theo độ lệch chuẩn thì học sinh lớp nào có điểm trung bình ít phân tán hơn?
Thầy Tuấn thống kê lại điểm trung bình cuối năm của các học sinh lớp 11A và 11B ở bảng sau:
a) Nếu so sánh theo khoảng biến thiên thì học sinh lớp nào có điểm trung bình ít phân tán hơn?
b) Nếu so sánh theo độ lệch chuẩn thì học sinh lớp nào có điểm trung bình ít phân tán hơn?
Quảng cáo
Trả lời:
Hot: 1000+ Đề thi cuối kì 2 file word cấu trúc mới 2026 Toán, Văn, Anh... lớp 1-12 (chỉ từ 60k). Tải ngay
CÂU HỎI HOT CÙNG CHỦ ĐỀ

Lời giải

Xét mẫu số liệu của cổ phiếu A:
Lời giải


Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.
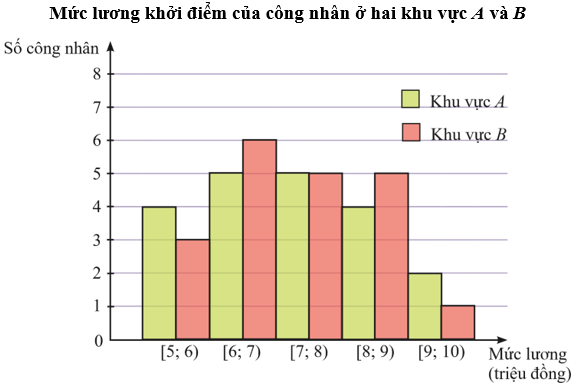
Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.

Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.

Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.