


















Biểu đồ dưới đây mô tả kết quả điều tra về mức lương khởi điểm (đơn vị: triệu đồng) của một số công nhân ở hai khu vực A và B.
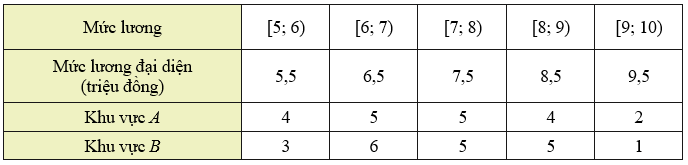
a) Hãy xác định giá trị đại diện cho mỗi nhóm và lập bảng tần số ghép nhóm cho mẫu số liệu đó.
b) Nếu so sánh theo độ lệch chuẩn của mẫu số liệu ghép nhóm thì công nhân ở khu vực nào có mức lương khởi điểm đồng đều hơn?
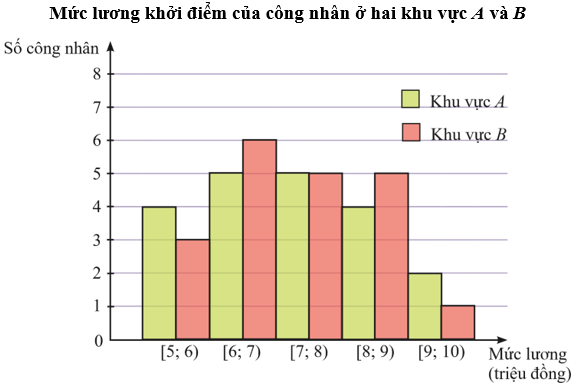
Biểu đồ dưới đây mô tả kết quả điều tra về mức lương khởi điểm (đơn vị: triệu đồng) của một số công nhân ở hai khu vực A và B.
a) Hãy xác định giá trị đại diện cho mỗi nhóm và lập bảng tần số ghép nhóm cho mẫu số liệu đó.
b) Nếu so sánh theo độ lệch chuẩn của mẫu số liệu ghép nhóm thì công nhân ở khu vực nào có mức lương khởi điểm đồng đều hơn?
Quảng cáo
Trả lời:
Hot: 1000+ Đề thi cuối kì 2 file word cấu trúc mới 2026 Toán, Văn, Anh... lớp 1-12 (chỉ từ 60k). Tải ngay
CÂU HỎI HOT CÙNG CHỦ ĐỀ

Lời giải

Xét mẫu số liệu của cổ phiếu A:
Lời giải


Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.

Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.
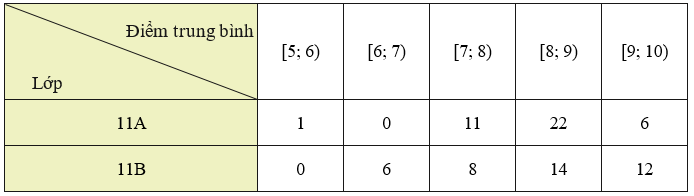
Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.

Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.