


















Kết quả khảo sát năng suất (đơn vị: tấn/ha) của một số thửa ruộng được minh hoạ ở biểu đồ sau.
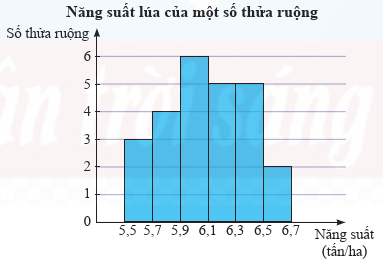
a) Có bao nhiêu thửa ruộng đã được khảo sát?
b) Lập bảng tần số ghép nhóm và tần số tương đối ghép nhóm tương ứng của mẫu số liệu trên.
c) Hãy xác định khoảng biến thiên, khoảng tứ phân vị và độ lệch chuẩn của mẫu số liệu trên.
Kết quả khảo sát năng suất (đơn vị: tấn/ha) của một số thửa ruộng được minh hoạ ở biểu đồ sau.
a) Có bao nhiêu thửa ruộng đã được khảo sát?
b) Lập bảng tần số ghép nhóm và tần số tương đối ghép nhóm tương ứng của mẫu số liệu trên.
c) Hãy xác định khoảng biến thiên, khoảng tứ phân vị và độ lệch chuẩn của mẫu số liệu trên.
Quảng cáo
Trả lời:
a) Có \(3 + 4 + 6 + 5 + 5 + 2 = 25\) thửa ruộng đã được khảo sát
b)


c) Khoảng biến thiên của mầu số liệu là: \(6,7 - 5,5 = 1,2\) (tấn/ha)
Cỡ mẫu \(n = 25\)
Gọi \({x_1};{x_2}; \ldots ;{x_{25}}\) là mẫu số liệu gốc về năng suất của 25 thửa ruộng được xếp theo thứ tự không giảm.
Ta có: \({x_1}; \ldots ;{x_3} \in [5,5;5,7);{x_4}; \ldots ;{x_7} \in [5,7;5,9);{x_8}; \ldots ;{x_{13}} \in [5,9;6,1);{x_{14}}; \ldots ;{x_{18}} \in [6,1;6,3)\); \({x_{19}}; \ldots ;{x_{23}} \in [6,3;6,5):{x_{24}};{x_{25}} \in [6,5;6,7)\)
Tứ phân vị thứ nhất của mẫu số liệu gốc là \(\frac{1}{2}\left( {{x_6};{x_7}} \right) \in [5,7;5,9)\). Do đó, tứ phân vị thứ nhất của mẫu số liệu ghép nhóm là: \({Q_1} = 5,7 + \frac{{\frac{{25}}{4} - 3}}{4}(5,9 - 5,7) = 5,8625\).
Tứ phân vị thứ ba của mẫu số liệu gốc là \({x_{19}} \in [6,3;6,5)\). Do đó, tứ phân vị thứ ba của mẫu số liệu ghép nhóm
là: \({Q_3} = 6,3 + \frac{{\frac{{3.25}}{4} - (3 + 4 + 6 + 5)}}{5}(6,5 - 6,3) = 6,33\).
Khoảng tứ phân vị của mẫu số liệu ghép nhóm là: \({\Delta _Q} = {Q_3} - {Q_1} = 0,4675\).
Số trung bình: \(\bar x = \frac{{3.5,6 + 4.5,8 + 6.6,0 + 5.6,2 + 5.6,4 + 2.6,6}}{{25}} = 6,088\).
Độ lệch chuẩn: \(\sigma = \sqrt {\frac{{{{5.75}^2} + {{10.125}^2} + {{9.175}^2} + {{4.225}^2} + {{2.275}^2}}}{{30}} - {{155}^2}} \approx 0,29\).
Hot: 1000+ Đề thi cuối kì 2 file word cấu trúc mới 2026 Toán, Văn, Anh... lớp 1-12 (chỉ từ 60k). Tải ngay
CÂU HỎI HOT CÙNG CHỦ ĐỀ

Lời giải

Xét mẫu số liệu của cổ phiếu A:
Lời giải


Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.
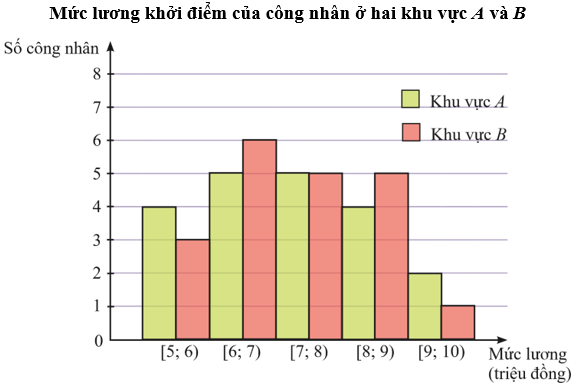
Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.

Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.
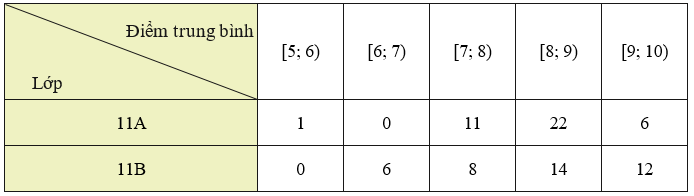
Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.

Lời giải
Bạn cần đăng ký gói VIP ( giá chỉ từ 250K ) để làm bài, xem đáp án và lời giải chi tiết không giới hạn.